Long long time ago, I can still remember, how I used to do Java Swing applications for living. Swing has a lot of strong points, and I really admire its design and architecture. When one needs to make a desktop application in Java, it still rocks. Of course, Swing is not bereft of annoyances. One of these is creating panels with complex layouts.
To my pleasant surprise, I had some Swing-related projects recently. So I revived an old open-source library of mine, which was originally hosted on Kenai.com (yes, that was that long ago). It was called “PanelMatic”, and it enjoyed a mild success back then.
So, PanelMatic is back. It’s using Java 11, it’s on GitHub, and it’s on its way to Maven Central. Below is an slightly modified intro that was published originally at Java.net (yes, that was that long ago).
PanelMatic 101
Every Swing developer knows this feeling: you’ve got the design of a UI panel. It’s the ‘right’ design. It ‘works’. It’s what the user would expect. Hell, it’s even what you would expect had you been the user. But it is going to be an awful lotta’ coding to lay it out in Swing – even before you take into consideration issue like panel re-sizing and localization.
Some developers nest numerous panels to get it working. Some try to “fake it” using the null layout (please, don’t). Others try to fit everything into a single panel and use the GridBagLayout – this involves quite a bit of trial-and-error, as can be seen in this documentary. Some even turn to graphical UI builders, which does not support dynamic panel creation, and whose designs are hard to maintain.
I’d like to suggest a slightly better solution: PanelMatic.
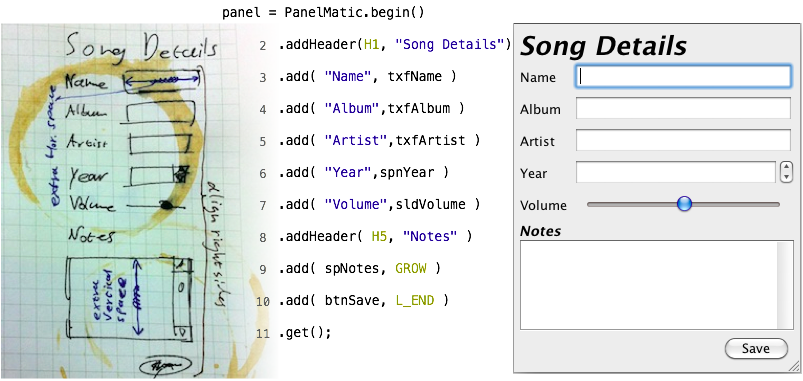
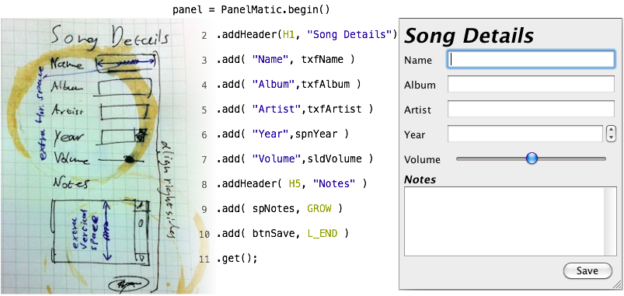
PanelMatic allows swing developers to create common UI panels with ease. Panels are built top-to-bottom (or, more precisely, on the page axis). There is an intuitive connection between the way the code looks and the way the created panel will look. Components can be added to the panel with a label and/or an icon (lines 3-7 in Figure 1), or alone (line 9). By default components stretch to occupy all the space they get, but this can be changed using modifiers (lines 9, 10). L_END (stands for “line end”) and GROW (stands for “grow”) are statically imported constants, and are in fact full-blown objects that implement the BehaviorModifier interface – so you can create your own modifiers if you need ’em. Client code can add headers (lines 2, 8) and flexible spaces (not shown). The default implementation uses a pluggable component factory to create all the extra components involved (e.g. JLabels), so you can customize them when the defaults won’t do.
As you’ve probably guessed, panels are built by builders that are obtained by invoking a static method on the PanelMatic class. PanelMatic is designed around an API/SPI approach – all the client code gets to hold is an interface, so the implementation can be changed without affecting client code at all. Builders are pooled, so you don’t have to think twice before asking for one. You can create your own implementation – just implement the service provider interfaces, and point the PanelMatic class to it. This can be done either by code or via a system property.
So this is PanelMatic. Use it to create common UI panels quickly, and use your freed up time to go to more meetings and catch up on some quality powerpoint presentations.
We could stop here, but we’d be missing half the fun.
Beyond Layout
PanelMatic’s approach to building UI panels allows for some surprising improvements over normal layout-based code. Here are some of my favorites.
Customizers, or Listening to All Components
Components are passed to the builder, and eventually get added to the produced panel. But before they are, they pass through a chain of PanelMaticComponentCustomizers, or “customizers”, for short. Each builder has two customizer chains – one that applies to all the panels it builds, and one for the current panel being built. The latter is disposed after the get() method is called. Customizers have a customize method, which gets an returns a JComponent. This allows client code to apply uniform customizations to all components in the created panel, or in the application in general. These customizations can be used for, e.g:
- Changing the background of the focused component
- Automatically wrap
Scrollables in aJScrollPane - Listen to all components in a panel
Let’s look into the latter example. A very common requirement is to have a “save” button enabled if and only if the user changed some data on the screen. This involves listening to all components the user can interact with. Normally, this requires a lot of boilerplate code. Instead, we can create a customizer that adds a change listener to every component added to the panel, and then add a single listener to that customizer. Incidentally, PanelMatic comes with such a customizer out of the box:
ChangeDetectorCustomizer cdc = new ChangeDetectorCustomizer();
panel = PanelMatic.begin( cdc )
.addHeader( H1, "Song Details")
.add("Name", txfName)
.add("Album",txfAlbum)
.add("Artist",txfArtist)
...
.add( btnSave, L_END)
.get();
cdc.addListener( new ChangeDetectorCustomizer.Listener() {
@Override
public void changeMade(ChangeDetectorCustomizer cdc, Object o) {
btnSave.setEnabled(true);
}});
The ChangeDetectorCustomizer adds the appropriate listeners to all common swing components, so any change made to any component makes the save button enabled. It also recurses down the containment hierarchy, so changes made to JCheckboxes nested in some sub-sub-sub-panel are detected as well.
Localizations
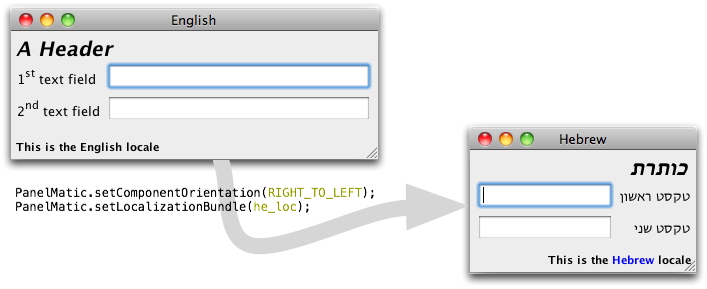
PanelMatic’s PanelBuilders can pass the labeling strings “as-is”, like we’ve seen so far, or use them as keys of a ResourceBundle. Resource bundles are set using static methods of the PanelMatic class itself, and affect all builders generated afterwards. The same goes for ComponentOrientation. So it takes only two lines of code to move from an English left-to-rigth UI to a right-to-left UI in Urdu/Hebrew/Arabic or any of the other RTL languages. That, and someone to translate the texts.
Building GUI Using Expressions – Anonymous Panels
PanelMatic allows panels to be created and laid out using a single expression. This is contrary to the normal UI construction process, where one first creates the panel, then applies a layout, and then adds sub-components – each in a statement of its own. The problem with statements is that they cannot be combined – they just sit there, one after the other, as if in a shopping list.
Expressions, on the other hand, can be nested and composed with other expressions. They are “first class citizens” in java, and can appear anywhere. So, one can create a sub panel while adding it to a bigger component:
JTabbedPane tabs = new JTabbedPane();
tabs.add( "Tab 1", PanelMatic.begin()
.addHeader(HeaderLevel.H1, "Tab 1")
.add("User Name", txfUserName )
.add("Password", txfPassword )
...
.get());This is somewhat similar to Anonymous Classes (those are the classes with no names that are created, say, when you implement an ActionListener). As anonymous panels can go anywhere, the below code works:
System.out.println("A panel with two JLabels would "
+ "have a preferred height of "
+ PanelMatic.begin()
.add( new JLabel("Label 1"))
.add( new JLabel("Label 2"))
.get().getPreferredSize().height + " pixels.");On my mac, it says:
A panel with two JLabels would have a preferred height of 40 pixels.Advanced Customizations
PanelMatic takes the “convention over configuration” approach. Everything can be customized, but you normally don’t need to bother with it. When you do, there are several levels of customizations available: one could subclass a PanelBuilderFactory (easy) or implement the entire stack (builders and factories) or get to some level in between. The exact details are beyond the scope of this article. Bottom line – as long as you can build your panel along the PAGE_AXIS, you can customize PanelMatic to build them. The client code should not be affected when you switch from the default implementation to yours.
Wrapping up
PanelMatic is a small library that allows swing developers to quickly create common UI panels. It helps with localizations and customizations and makes the code creating the UI readable and intuitive. It’s easy to pick up and hard to put down, though I might be slightly biased. Why not give it a go and see for yourself?
https://github.com/codeworth-gh/PanelMatic